

像修車先找故障點,AI 也需系統化診斷。
在台灣,越來越多企業把 Agent(代理人)從 PoC(概念驗證)推進到正式上線;但很多團隊仍陷入「無限修 Bug」的循環,優化進度緩慢且難以複製。AI 不是萬能的靈丹妙藥。即使最先進的 LLM(大語言模型)Agent 也需要團隊根據場景做量身校準。這篇文章協助你建立一套可重複、可量化的錯誤分析流程,讓經驗變成 SOP,團隊才能持續進步。

傳統除錯像找漏水點,錯誤分析像用熱顯像儀一次看全局。
LLM 輸出多變,傳統測試難全面覆蓋。
傳統除錯(Debugging)強調重現問題並逐步定位,但 LLM Agent 的輸出常帶隨機性,單元測試難以全面覆蓋所有情境。因此建議先做錯誤分析,再依分析結果設計對應的 Evals(評估)測試案例。
先找核心問題,再設計對症測試。
如果沒有先進行錯誤分析,測試案例很容易流於形式,無法真正找出系統的核心問題。錯誤分析能幫助團隊聚焦在最值得投入資源的優化點。
像醫生分辨病因,才能對症下藥。
Andrew Ng 曾用「貓狗辨識」案例說明:他檢查錯誤圖片並歸類,發現 50% 是狗被誤判成貓,30% 是大型貓科誤判,20% 是圖片模糊。這說明,透過錯誤分類可明確找到優化重點,而非盲目增加資料量。

觀測性像儀表板,讓你隨時掌握系統健康。
現代 AI 系統講求觀測性(Observability),即時掌握運作狀態與錯誤分布,才能有效追蹤品質指標並持續優化。
AI Evals 看單點,Agent Evals 看整體。

AI Evals:針對單一模型或任務的評估流程,目的是量化或質化模型在特定任務/情境下的表現。常見指標如準確性、偏誤性、困惑度,通常用於模型訓練或微調階段。但 AI Evals 多基於靜態資料集,無法捕捉代理人系統的動態互動。

Agent Evals:設計給多流程、會呼叫外部工具的代理人系統(Agent),以任務層級評估整體表現。關注 RAG(檢索增強生成)正確率、任務完成率、業務理解、工具調用正確性、多輪一致性等。更適合複雜企業應用與動態環境。
像烹飪有食譜,錯誤分析也有步驟。
每一步都需確保樣本具代表性、錯誤分類具體可操作,並能以明確品質指標追蹤成效。

先收集證據,再請專家判斷問題源頭。
一般通用的 LLM 難以快速確認錯誤來源,但如果使用 AltaBots.ai,內建的日誌功能可以協助你多維度篩選並迅速找到異常對話,大幅提升錯誤分析與優化效率。
挑樣本就像抽血檢查,要有代表性才能反映全身狀況。建議從大量日誌中挑 100–200 筆具代表性的樣本,涵蓋各種常見場景與問題。
人工標註請聚焦「第一個失敗點」,避免模糊詞(如「回覆不準」);請改以具體描述(例如「未理解客戶意圖,導致錯誤轉交」)。標註時也應包含可執行的修正建議,利於後續改善。

分類錯誤像整理衣櫃,先處理最多的問題。
LLM 幫你自動整理問題清單,省時又全面。將人工標註結果交給 LLM,協助歸納出系統性失敗模式,並依頻率排序,聚焦最影響體驗的問題。
可直接修正的問題(例如 prompt 拼字錯誤、格式不符),建議先修正(Fix);主觀或需長期追蹤的問題(如回覆禮貌、資訊正確),則建立 Evals 測試案例,由 LLM Judge 持續監控。

自動評審像品管線,品質監控不中斷。
業界常用兩種方法,像 AI 當裁判或用標準答案驗證。
AI 幫 AI 打分數,省時又能自動化。通常以 TRUE/FALSE(二元判定)為主,而非 1–5 分制。實務上建議避免分數制,因為定義分數區間成本高且易引爭議;二元判斷更利於自動化與追蹤。需定期人工抽樣審核,確保人機判斷一致(建議達 90% 以上)。
有標準答案的任務,就用黃金資料集直接比對。適合 SQL、RAG 等可明確定義對錯的任務。優點是高精度、可自動化,缺點是需投入人力維護資料集,難涵蓋開放式問答。
評估標準要像紅綠燈一樣明確,才能自動判斷通過與否。設計 LLM Judge 時,應明確定義二元判斷與品質指標,並與人工標註比對,達到一致性門檻才正式導入。
把評估流程自動化,像工廠品管線一樣持續監控品質。每次模型或 prompt 更新後,務必重新執行回歸測試,確保舊問題不會復發。
一張表看懂兩種評估方式的差異。
下表整理 AI Evals 與 Agent Evals 的核心差異,供讀者快速比較:

兩種方法各有優缺點,靈活搭配效果最好。
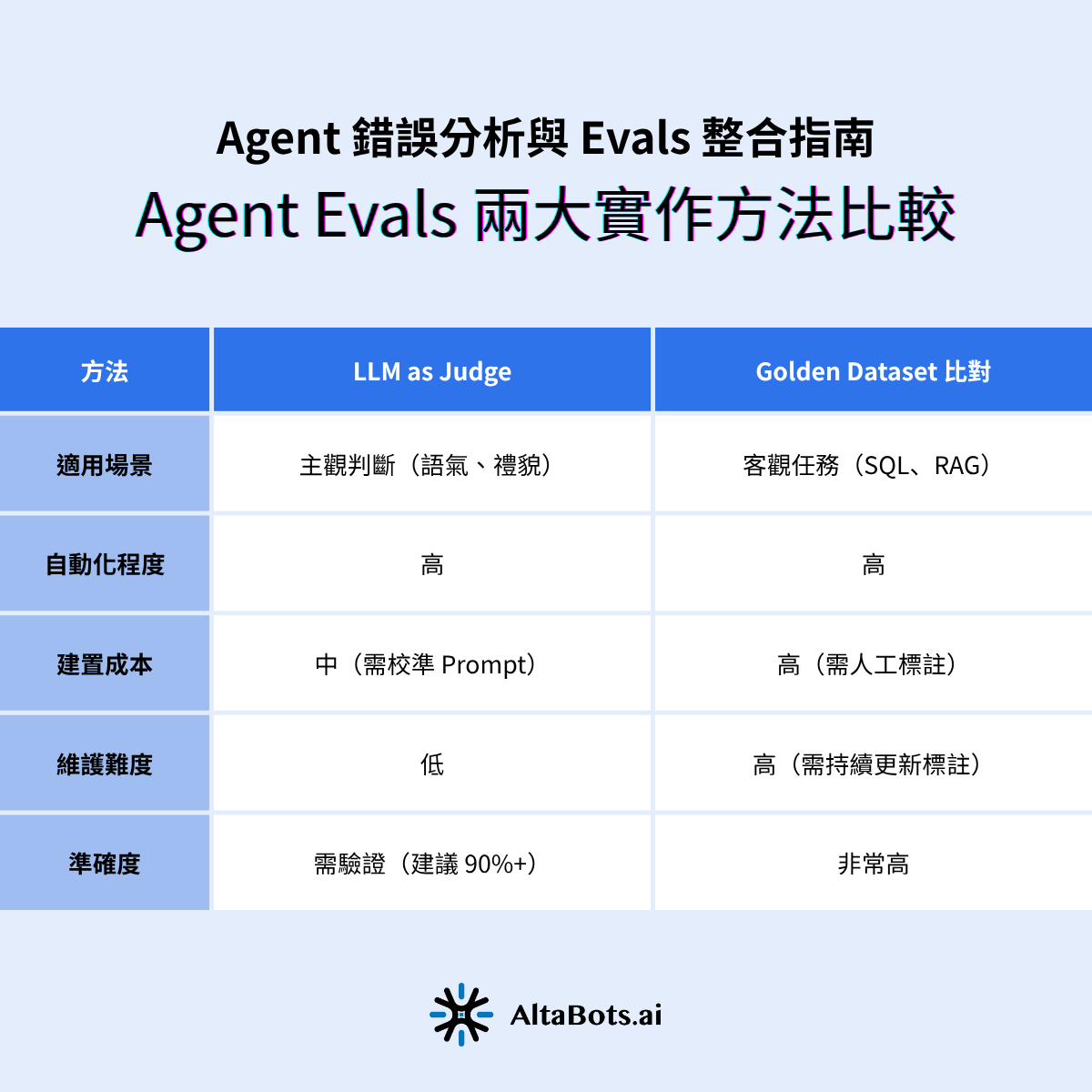
💡 建議:兩種方法可組合使用——用 Golden Dataset 驗證關鍵路徑,用 LLM Judge 監控全局品質。
許多人認為只要有 LLM 或 AI 工具就能自動完成評估,這是錯誤的。AI 缺乏產品上下文與專業知識,無法判斷如「虛擬看房」等產品功能是否真實存在。初期階段仍需人類專家(Benevolent Dictator)參與,確保標註品質。
分數等級制會造成指標混亂且難以追蹤,3.2 分與 3.7 分的差異難以解釋。建議 LLM Judge 僅針對單一失敗模式,並採用二元(True/False)結果,提升一致性與自動化效率。
僅看總體一致性會忽略長尾錯誤。建議分析不一致矩陣(misalignment matrix),檢查人類與 LLM Judge 的所有交叉情境,並持續優化 Prompt,確保評估結果可靠。
大型委員會標註流程昂貴且緩慢,建議由具備領域專業的產品經理(Benevolent Dictator)主導,提高效率與標註品質。
Evals 不僅是單元測試,更是系統性衡量與優化產品品質的工具。AB 測試、線上監控、用戶行為追蹤等都屬於 Evals 範疇,應以數據科學思維持續優化。
建立可持續優化的團隊流程,讓錯誤分析成為 AI 系統成長的核心動力。
在實務導入過程中,許多團隊容易落入「只寫測試,卻沒抓到真問題」的陷阱。常見挑戰包括:
要讓錯誤分析真正為 AI Agent 系統帶來成長,建議團隊從數據治理、標註規範、評估指標、跨角色協作與持續監控等層面著手,並善用如 AltaBots.ai 這類具備多維度觀測功能的 AI Agent 開發平台,提升分析效率。
錯誤分析不只是修 Bug 的工具,更是驅動 LLM Agent 系統持續成長的核心引擎。唯有建立結構化、可複製、可持續優化的流程,團隊才能在面對複雜多變的 AI 應用場景下,持續提升產品品質與用戶體驗。
如果您想了解更多或申請試用帳號,請您填寫以下資訊,將由專人跟您聯繫!
